Menu
Disaster Recovery is the process, policies and procedures an organization uses to prepare for recovery or the continuation of the operation of their IT Assets (applications, software, data, and/or technology infrastructure, including the data center facilities) that are needed to resume the performance of normal business functions after the event of either a disaster or an outage resulting from a technology or data center failure.
While Disaster Recovery plans, or DRPs, often focus on bridging the gap where IT assets have been damaged or lost, one cannot forget the vital element of people that composes much of any IT organization. A building fire might predominantly affect vital data storage; whereas an epidemic illness is more likely to have an effect on staffing. Both types of disasters need to be considered when creating a Disaster Recovery Plan (DRP). Thus, organizations should include in their DRPs contingencies for how they will cope with the sudden and/or unexpected loss of key personnel as well as how to recover their IT assets and return them to an acceptable operating state. The Tri-Paragon DRP Assessment Team have actually experienced and resolved numerous disasters including floods, earthquakes and fires making them uniquely qualified to perform your DRP Assessment.

The Tri-Paragon DRP Assessment focuses on the capabilities of the plans, the process of maintaining them, the frequency of their validations, results of their validations and the determination of whether or not the move to a DR site is, in fact, recoverable. Most organizations focus on a major outage of a facility. Untimely outages of critical applications or their underlying infrastructure can also severely damage a Company’s credibility and cause significant customer loss. Critical IT asset outages have to be assessed separately and the duration of the outage impacts quantified accordingly.

The DRP should include the identification of risks associated with various types of disaster interruptions that may occur, the potential for the risk to occur, the impacts if it did occur and the planned recovery approach or mitigation strategy. This process is based on a Governance, Risk, and Compliance (GRC) management methodology. The Tri-Paragon DRP Assessment Team works closely with the customer’s assigned resources in a workshop environment to assist in the performance of a self-assessment.

The assessment of the Disaster Recovery plan is focused on the IT organization and goes hand in hand with a Single Points of Failure Analysis. The assessment results in a comprehensive report identifying the gaps in the recovery and DRP maintenance processes, the costs and impacts should an interruption occur and the steps required to mitigate the issues. Each application is assessed separately and a risk profile created to enable the Company to understand its risks of individual application outages and/or data loss and the impacts these outages may have on the overall functioning and financial impact of the business.

Many companies that aren’t effectively prepared for disaster situations simply cannot bounce back from a significant crisis. Without an adequate Disaster Recovery Plan statistics have shown that 75% of organizations experiencing a major disaster typically go out of business within 3 years.
A Tri-Paragon IT Disaster Recovery Assessment includes:
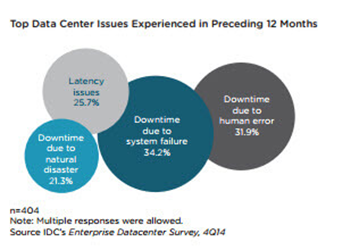
Even with the help of modern technology, data centre operations are still hampered by sporadic and persistent issues that demand immediate attention. Of all these issues, unplanned downtime is the most pressing. Businesses should ensure seamless end-user experience and line-of-business operations.
As shown in the following figure, downtime is the most common issue faced by data centre operators. The respondents cited that downtime is caused by system failure, human error, and natural disasters.
It’s hard to keep your operations up if you’re using an old and unstable IT infrastructure with inadequate monitoring tools. On the other hand, an efficiently modeled data centre that needs continuous process improvement can also contribute to system failure. Eliminating these inefficiencies in your system can greatly help in minimizing unplanned downtime. Preparing a data centre strategy and roadmap eliminates unexpected expenses due to system failure by proactively planning for continuous improvement.
The reality is that system downtime can often be correlated to human error. Data centre operators must have flawless processes and execution to ensure the systems are maintained, repaired, tested, and monitored 24/7. Oftentimes, downtime is a result of multiple breakdowns in processes or human execution. An assessment of your data centre processes identifies and resolves gaps which can lead to unexpected downtime.
Natural disasters are inevitable—even if it’s “man-made” like major power grid outages. Having a robust disaster recovery plan in place can prepare you for the inevitable. Implementing and validating your DR strategy and processes can go a long way to prevent unnecessary outages due to natural disasters.
FACT #4: SUSTAINING 100% UPTIME IS NOT MISSION IMPOSSIBLE.
Maintaining 100% uptime can be achieved through detailed planning, system maintenance and management by an experienced staff of data centre professionals. While automation and systems redundancy are important, experienced data centre professionals are the most important ingredient to maintaining uptime.6

IDC’s survey on The Problems of Downtime and Latency in the Enterprise Datacentre mentioned these essential guides to ensure 100% uptime6:
1. Prevent system failure.
To have an efficient and reliable data centre, regular monitoring and updating of critical system infrastructure is a must. Automation and centralized monitoring solutions can also help in preventing system failure.
2. Reduce human error
Documenting and following standard methods and procedures is critical to maintaining uptime. A recurring assessment process must be in place to validate the standard methods and procedures to ensure they are being updated as necessitated. Oftentimes, data centre operators will become overly dependent on systems to maintain uptime. The reality is that more oftentimes than not, a human error is involved in a system or process breaking down. Operators can reduce downtime by ensuring experienced professionals are monitoring, maintaining, and managing the power, cooling, and infrastructure 24/7.
3. Ensure robust disaster planning.
Having a disaster recovery plan in place for potential natural disasters and other impacting events is critical. Being proactive, such as ensuring that backup diesel generators are tested regularly (and for an adequate duration) and taking precautionary steps ahead of anticipated natural disasters can minimize downtime.
Following this critical methodology can ensure that you stay online when crisis does strike. Planning, automation, and system redundancy are important strategies in reducing or eliminating downtime. Managing redundant and resilient systems with an experienced technical staff can ensure that operations are always up and operating.
COLOCATING should be WITH A REDUNDANT AND COMPLIANT DATA CENTRE.
Colocation offers services that can augment your existing systems. Most colocation facilities are designed with a resilient critical system, a redundant battery backup and cooling system, and with a scalable infrastructure that you can take advantage of. Leading colocation sites offer 100% uptime with the help of their robust infrastructure. Even though this may provide a level of security around uptime there is still a need to have a resilient backup and disaster recovery plan in place for workloads assigned to a colocation environment.
CONCLUSION
These cold, hard facts about downtime demonstrate the importance and challenge of keeping applications up and running with 100% availability. Downtime has serious consequences and can cost businesses in lost revenue, lost customers, and brand loyalty.
Tri-Paragon aids in the following areas to assist in achieving your uptime objectives:
Please give us a call at 416 865-3392 or send us an email at info@triparagon.com
Copyright 2016 © Tri-Paragon Inc.. All Rights Reserved.
Web Design and Domain names by 